ByteDancer
后端开发 - 视频二面c++
多态、虚函数
多态底层实现:动态绑定,运行时才把方法调用与方法实现关联起来。
- 编译时多态:方法重载,有多个同名的方法,在编译时根据参数确定调用哪个方法。
- 运行时多态:方法重写,子类重写父类的方法,当父类引用指向子类对象时,只有在运行时才能确定调用哪个方法。
虚函数表存放在哪里?全局数据区。虚函数表类似一个数组,类对象存储了指向虚函数表的指针。虚函数表vtable在Linux/Unix中存放在可执行文件的只读数据段中(rodata),微软的编译器将虚函数表存放在常量段。
构造函数可以是虚函数吗?构造函数不能声明为虚函数,析构函数可以声明为虚函数,而且有时是必须声明为虚函数(一面中有案例)。构造函数不能声明为虚函数的原因:
A virtual call is a mechanism to get work done given partial information. In particular, “virtual” allows us to call a function knowing only an interfaces and not the exact type of the object. To create an object you need complete information. In particular, you need to know the exact type of what you want tocreate. Consequently, a “call to a constructor” cannot be virtual. 虚函数的作用在于通过子类的指针或引用来调用父类的那个成员函数。而构造函数是在创建对象时自己主动调用的,不可能通过子类的指针或者引用去调用。
数据库
建立索引的原则
- 表的主键外键必须有索引;
- 数据量过多的表应该有索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引;
- 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
- 索引应该建在选择性高的字段上; 为经常需要排序、分组和联合操作的字段建立索引;
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
- 复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
- 频繁进行数据操作的表,不要建立太多的索引;
- 删除无用的索引,避免对执行计划造成负面影响;
对性别建立索引
理论上,重复率高的字段不适合建索引。
但是,如果把性别字段设为表的聚集索引,那么就肯定能加快大约一半该字段的查询速度了。聚集索引指的是表本身中数据按哪个字段的值来进行排序。因此,聚集索引只能有一个,而且使用聚集索引不会付出额外IO开销。
链接:https://www.jianshu.com/p/4305bedeb5c9
对身份证号建立索引
身份证长度太长,不适合做索引。
对于长度较长的字符串建立索引:
- 前缀索引
- 倒序存储
- 哈希存储
- 字段拆分
如果维护系统是一个市政系统,前6位区分度不高,浪费空间。身份证后六位区分度高,将身份证倒序存储,然后索引为id_card(6):select from user where id_card = reverse(‘输入的正序身份证号码’);倒序存储只适用等值查询。新增一个字段存储身份证号码的哈希值,加上索引,存入身份证时候,对身份证进行crc3()计算,得到的值存入id_card_crc,索引长度为4,因为hash可能会发生碰撞,所以查询时候加上身份证作为筛选条件:select from user where id_card_crc = crc32(“输入的身份证号码”) and id_card = ‘输入身份证号’;哈希存储只适用等值查询。拆分存储,将区分度高的,比如后六位单独存储。
乐观锁和悲观锁
乐观锁:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。
常见实现方式:
版本号机制:一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
CAS算法:即compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数:需要读写的内存值 V、进行比较的值 A、拟写入的新值 B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
版本号机制(如果有两个线程同时改变了版本号?)
乐观锁本身是不加锁的,只是在更新时判断一下数据是否被其他线程更新了;所以如果没有线程安全方面的
保护会出现ABA问题(如果另一个线程修改V值假设原来是A,先修改成B,再修改回成A。当前线程的CAS操作无法分辨当前V值是否发生过变化。)导致乐观锁失效,可行方法是在线程安全上进行保护处理。
计算机网络
如果有10M数据, 允许丢包,应该使用哪种方法?
send/sendto/recv/recvfrom
一般情况下:
send(),recv()用于TCP,sendto()及recvfrom()用于UDP,但send(),recv()也可以用于UDP,sendto()及recvfrom()也可以用于TCP
TCP中一端用send函数向另一端发送消息,recv用于接收;
sendto和recvfrom一般用于UDP协议中,但是如果在TCP中connect函数调用后也可以用.
理论上UDP报文最大长度是65507字节,虽然在实际应用中sendto确实会切片分包,但是考虑到理论问题那就还是用TCP的send吧,毕竟TCP面向字节流对包的大小没有限制
面向报文和面向流
面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会是IP太小。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
面向字节流的话,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP也可以等待积累有足够多的字节后再构成报文段发送出去。
操作系统
Windows可以删除正在使用的文件吗?
可以,强制删除方法
如果要实现文件系统,可以删除正在使用的文件,如何实现?
无法被删除是因为有其他进程正在占用这部分资源,在内存中的表现应为不可写,所以重点在这里进行改进
编程
给一个未排序的整数数组,找第一个缺失的正数,要求时间复杂度O(n),空间复杂度O(1)。
将数组视为哈希表,哈希函数的规则:将数值 i 映射到下标 i-1。
在对于下标为i的位置进行映射时,不断交换直到nums[i] == i+1,或者,遇到负数、遇到大于size的数、当前数值应放的位置上已经是正确的数值。
最后遍历一遍数组,第一个遇到的值不等于下标+1的那个数,就是缺失的第一个正数。
1 | int firstMissingPositive(vector<int>& nums) { |
难顶。
这次,可能,真的,有点,凉。
另外,ios一面问到的的两个算法题:
- 上楼梯——动态规划求解
- 多个闭区间求并集——先排序,然后左右端点依次比较
Tencent
后端开发 - 电话一面编译原理
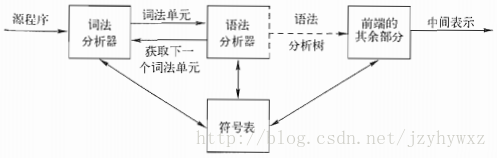
词法分析
词法分析使用状态转换图来识别单词符号。
对于输入的字符串,按照构词规则将其分解为一系列单词符号,包括关键字、标识符、运算符、常量等。输出单词符号常常表示成: (单词种别,单词符号的属性值)。

用lex做词法分析,mylexer.l 文件被%%分成三个区域:declarations section、rules section、programs section
冲突解决规则:
1) 总是选择最长的前缀
2) 如果最长的可能前缀与多个模式匹配,总是选择Lex中先被列出的模式。
语法分析
语法分析器从词法分析器获得一个词素序列,并验证这个序列是否可以由源语言的文法生成。语法分析器会构造一棵语法分析树,并把它传递给编译器的其他部分进一步处理,在构建语法分析树的过程中,就验证了这个词素序列是否符合源语言的文法。
上下文无关文法(context-free grammar, CFG),四元组(N, T, P, S)
分析方法:
c++
类的大小
- 空类A,sizeof(A)=1,默认空类有一个占位符。
- 类A中只有静态成员变量,sizeof(A)=1,因为静态成员变量在全局存储区,A相当于空类。
- 类A中只有一个虚函数,sizeof(A)=4,任何含有虚函数的类都有一个虚函数表指针。
- 类A中有一个char变量、一个int变量,sizeof(A)=8,高位对齐。
- 空类C虚拟继承类A,sizeof(C)=4,因为空类C含有虚函数表指针。(虚拟继承的提出是为了解决多重继承中的内存空间浪费问题)
- 派生类A,sizeof(A)等于A的每个父类大小之和。
重载&覆盖&隐藏
- 重载:不同函数使用相同的函数名,但函数的参数个数或类型不同,调用时根据参数来区别函数。
- 覆盖:在派生类中对积累的虚函数重新实现,函数名和参数都一样,函数体不同。
- 隐藏:派生类中的函数把积累中同名的函数屏蔽掉了。 这这这……这情况我写过但我不知道他叫隐藏啊……想起了“常驻内存”……
const
放在函数前、函数后、参数前有什么区别?
- 类成员函数,const放在函数体后面时,则不允许对数据成员进行修改。
- const修饰函数参数时,不能修改传进来的值。(常用语参数为指针或引用的情况)。
- const放在函数前,用于修饰返回值(多用于二目操作符重载函数并产生新对象的时候)。
数组
int a[10],sizeof(a)/sizeof(int)=10,若a作为函数参数传入,则sizeof(a)/sizeof(int)=1.
数据结构
STL
list vs vector:
- vector基于数组实现,占用连续的内存空间,支持随机存取,插入和删除操作需要进行内存块拷贝。若进行插入操作,需要内存扩充时,容量会变成原来的1.5倍(vs)或2倍(gcc)。
- list基于双向链表实现,在内存中离散存储,不支持随机访问,插入和删除的效率高。
hashmap
哈哈又问hashmap怎么实现了:
hasnmap是一个链表的数组,对于每个 key-value对元素,根据其key的哈希,该元素被分配到某个桶当中,桶使用链表实现,链表的节点包含了一个key,一个value,以及一个指向下一个节点的指针。当桶的大小大于8时会转化为红黑树存储数据。
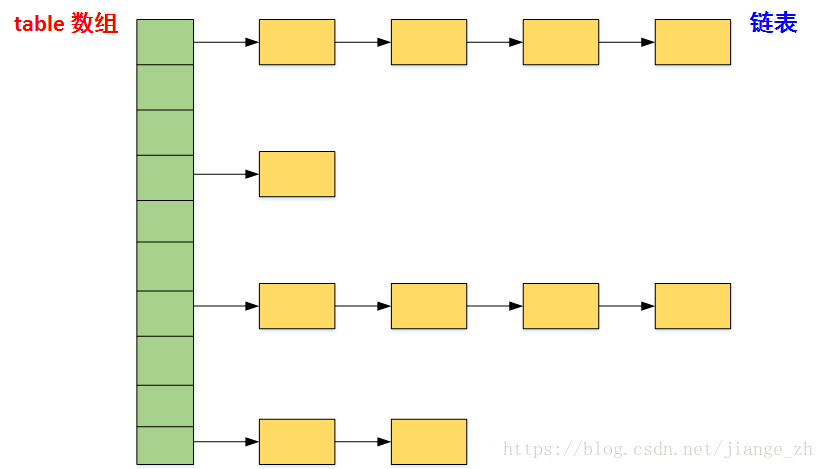
- https://blog.csdn.net/jiange_zh/article/details/81588983
- https://blog.csdn.net/daiyuhe/article/details/89424736
https://www.jianshu.com/p/8b372f3a195d
平衡二叉树
n个节点的平衡二叉树,叶子结点数量,树的高度
插入流程:https://blog.csdn.net/qq_34840129/article/details/80728186
有向图
拓扑
找环
http://www.hongyanliren.com/2014m07/11402.html
计算机网络
三次握手四次挥手
三次握手
进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。实质上其实就是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号,交换TCP窗口大小信息。刚开始客户端处于 Closed 的状态,服务端处于 Listen 状态。
第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c)。此时客户端处于 SYN_SEND 状态。首部的同步位SYN=1,初始序号seq=x,SYN=1的报文段不能携带数据,但要消耗掉一个序号。
第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s)。同时会把客户端的 ISN + 1 作为ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_RCVD 的状态。在确认报文段中SYN=1,ACK=1,确认号ack=x+1,初始序号seq=y。
第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 ESTABLISHED 状态。服务器收到 ACK 报文之后,也处于 ESTABLISHED 状态,此时,双方已建立起了连接。确认报文段ACK=1,确认号ack=y+1,序号seq=x+1(初始为seq=x,第二个报文段所以要+1),ACK报文段可以携带数据,不携带数据则不消耗序号。
四次挥手
刚开始双方都处于 ESTABLISHED 状态,假如是客户端先发起关闭请求。四次挥手的过程如下:
第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于 FIN_WAIT1 状态。即发出连接释放报文段(FIN=1,序号seq=u),并停止再发送数据,主动关闭TCP连接,进入FIN_WAIT1(终止等待1)状态,等待服务端的确认。
第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 +1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT 状态。即服务端收到连接释放报文段后即发出确认报文段(ACK=1,确认号ack=u+1,序号seq=v),服务端进入CLOSE_WAIT(关闭等待)状态,此时的TCP处于半关闭状态,客户端到服务端的连接释放。客户端收到服务端的确认后,进入FIN_WAIT2(终止等待2)状态,等待服务端发出的连接释放报文段。
第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。即服务端没有要向客户端发出的数据,服务端发出连接释放报文段(FIN=1,ACK=1,序号seq=w,确认号ack=u+1),服务端进入LAST_ACK(最后确认)状态,等待客户端的确认。
第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 +1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。即客户端收到服务端的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),客户端进入TIME_WAIT(时间等待)状态。此时TCP未释放掉,需要经过时间等待计时器设置的时间2MSL后,客户端才进入CLOSED状态。
MSL:Maximum Segment Lifetime,报文最大生存时间,Windows : MSL = 2 min,linux(Ubuntu, CentOs) : MSL = 60s,Unix : MSL = 30s。
CLOSE_WAIT
进入到close_wait状态后,服务器需要查看自己是否还有数据要发送给对方,如果没有的话就可以关掉socket链接,发送FIN给客户端。在客户端连接关闭之后,程序里没有检测到,或者程序压根就忘记了这个时候需要关闭连接,于是这个资源就一直被程序占着。一般是代码的问题。
拥塞控制&流量控制
流量控制是由接收方控制的,发送方始终是被迫调整至与接收方同步。流量控制解决的只是过快的发送方的问题,思路也很简单,得到ACK确认来调整发送速率,对于未收到的包再重传。
拥塞控制可以针对以下几种典型的情景:
- 两组通信共享一个无限缓存的路由器,那么这里的拥塞问题仅仅是由于链路容量,分组到达速率接近链路容量时会出现巨大的排队时延。
- 当路由器的缓存有限时,还可能因为发送速率过快导致缓存溢出,这时会增加一个分组重传开销。
- 在路由器缓存容量有限的多跳网络中,如果一个分组沿着一条路径被丢弃,那么该路径上其他参与转发该分组的路由的缓存资源也被浪费了,这在一定程度上也引起了拥塞。
HTTPS工作原理
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)以安全为目标的HTTP通道,HTTP的安全版本。HTTPS由两部分组成的:HTTP+TLS/SSL,即HTTP下加入TLS/SSL层,HTTPS的安全基础就是TLS/SSL。服务端和客户端的信息传输都会通过TLS/SSL进行加密,所以传输的数据都是加密之后的数据。
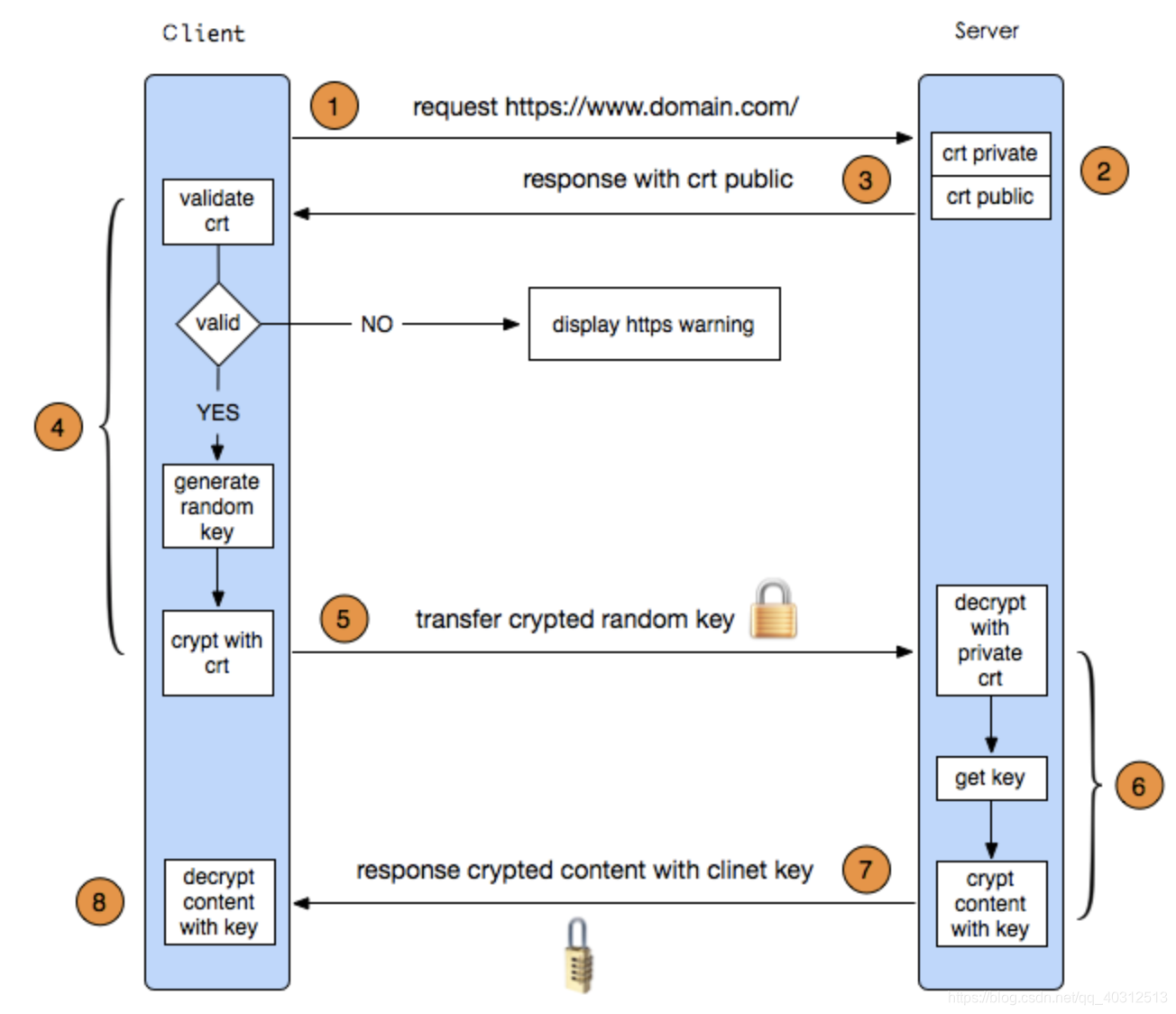
https://www.cnblogs.com/xrq730/p/5041921.html
算法
两个单向链表判断是否相交
双指针法:链表A: a+c,链表B : b+c, a+c+b = b+c+a
如果两链表不相交的话,即c = 0,当两个指针都走完 a+b 的路程后,会同时处于两链表的末端,出现这种情况就直接返回nullptr。
1 | ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { |
Anyway,enjoy it.