ListNode* reverseBetween(ListNode* head, int m, int n){ if (m == n)return head; ListNode* prehead = new ListNode(0); prehead->next = head; int i = m; ListNode* front = prehead; while (i) { front = front->next; i--; } stack<int> s; ListNode* back; back = front; int k = n - m; while (k) { s.push(back->val); back = back->next; k--; } s.push(back->val); while (!s.empty()) { front->val = s.top(); s.pop(); front = front->next; } return prehead->next; }
vector<vector<int>> subsetsWithDup(vector<int>& nums) { sort(nums.begin(), nums.end()); vector<vector<int>> res = { {} }; for (int i = 0; i < nums.size(); i++) { int k = res.size(); while (k--) { res.push_back(res[k]); res[k].push_back(nums[i]); } } sort(res.begin(), res.end());
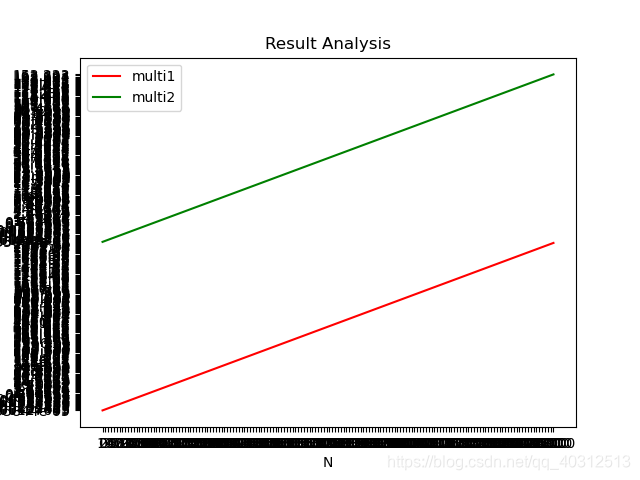
a = importdata('E:\桌面\时光以南\Parallel并行\实验\work1\multi1.txt'); x = a(:,1); y = a(:,2); plot(x,y,'r');hold on; b = importdata('E:\桌面\时光以南\Parallel并行\实验\work1\multi2.txt'); m = b(:,1); n = b(:,2); plot(m,n,'g');hold off;
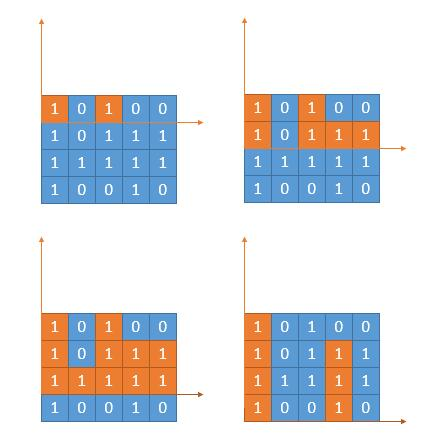
intmaximalRectangle(vector<vector<char>>& matrix){ int row = matrix.size(); if (!row)return0; int col = matrix[0].size(); if (!col)return0; vector<vector<int>> count; for (int i = 0; i < row; i++) count.push_back({ (matrix[i][0] - '0') }); for (int i = 0; i < row; i++) { for (int j = 1; j < col; j++) { if (matrix[i][j - 1] == '0') count[i].push_back(matrix[i][j] - '0'); else count[i].push_back(count[i][j - 1] + matrix[i][j] - '0'); } }
int res = count[0][0]; for (int i = 0; i < row; i++) { for (int j = 0; j < col; j++) { if (matrix[i][j] == '1') { int width = count[i][j]; for (int k = i; k >= 0; k--) { if (matrix[k][j] == '0')break; width = count[k][j] < width ? count[k][j] : width; int area = width * (i - k + 1); res = area > res ? area : res; } } } } return res; }
//The end criterion is the case of a one-dimensional vector: template <typename T> classDotProduce<1, T>{ public: static T result(T* a, T* b){ return *a * *b; } };