voiddfs(int s, int t, Ans &A, vector< Ans > &paths, int start) { if (s == t) { A.start = start; A.getCost(); paths.push_back(A); }
for (int i = 0; i < G4[s].size(); i++) { int u = G4[s][i].to; if (!vis[u]) { vis[u] = true; A.link.push_back(u); dfs(u, t, A, paths, start); A.link.pop_back(); vis[u] = false; } } }
boolneighbour(string s1, string s2) { bool flag = true; int i = 0; //所有单词具有相同的长度 while (i < s1.length()) { if (s1[i] != s2[i]) { if (flag) flag = false; else returnfalse; } i++; } returntrue; } vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) { //beginWord 和 endWord 是非空的,且二者不相同 int source = 0; int vsize = wordList.size(); for (; source < vsize; source++) { if (wordList[source] == beginWord)break; } if (source == vsize) { wordList.push_back(beginWord); vsize++; } int destination = 0; for (; destination < vsize; destination++) { if (wordList[destination] == endWord)break; } if (destination == vsize)return {}; nV = vsize;
//这里假设beginWord 和 endWord不在wordList中
//build graph for (int i = 0; i<vsize; i++) { for (int j = i; j<vsize; j++) { G1[i][j] = G1[j][i] = INF; } } for (int i = 0; i < vsize; i++) { for (int j = i + 1; j < vsize; j++) { if (neighbour(wordList[i], wordList[j])) { addEdge(i, j, 1, G); G1[i][j] = G1[j][i] = 1; } } } //get new graph dijkstra(source, G);
//Yen算法 vector<vector<string>> res; vector<Ans> paths; Ans ans; memset(vis, false, sizeof(vis)); dfs(source, destination, ans, paths, 1);
for (int i = 0; i<paths.size(); i++) { vector<string> tmp = { beginWord }; for (int j = 0; j<paths[i].link.size(); j++) { tmp.push_back(wordList[paths[i].link[j]]); } res.push_back(tmp); } return res; } intsingleNumber(vector<int>& nums){ int res = 0; for (int i = 0; i<nums.size(); i++) res ^= nums[i]; return res; } intladderLength(string beginWord, string endWord, vector<string>& wordList){ unordered_set<string> dict(wordList.begin(), wordList.end()); if (dict.find(endWord) == dict.end()) return0; // 初始化起始和终点 unordered_set<string> beginSet, endSet, tmp, visited; beginSet.insert(beginWord); endSet.insert(endWord); int len = 1;
while (!beginSet.empty() && !endSet.empty()) { if (beginSet.size() > endSet.size()) { tmp = beginSet; beginSet = endSet; endSet = tmp; } tmp.clear(); for (string word : beginSet) { for (int i = 0; i < word.size(); i++) { char old = word[i]; for (char c = 'a'; c <= 'z'; c++) { if (old == c) continue; word[i] = c; if (endSet.find(word) != endSet.end()) { return len + 1; } if (visited.find(word) == visited.end() && dict.find(word) != dict.end()) { tmp.insert(word); visited.insert(word); } } word[i] = old; } } beginSet = tmp; len++; } return0; }
boolisPalindrome(string s){ bool res = true; int i = 0, j = s.length() - 1; transform(s.begin(), s.end(), s.begin(), ::toupper); while (i < j) { while (i<j&&!isalnum(s[i]))i++; while (i<j&&!isalnum(s[j]))j--; if (s[i] != s[j])returnfalse; i++; j--; } return res; }
使用 val 来记录全局最大路径和。lmr表示路径:left->middle->right,return表示路径:由左/右子树经过当前节点向上走。
1 2 3 4 5 6 7 8 9 10 11 12 13
inthmax(TreeNode* root, int &val){ if (root == nullptr)return0; int left = max(hmax(root->left, val),0); int right = max(hmax(root->right, val),0); int lmr = root->val + left + right; val = max(val,lmr); return root->val + max(left, right); } intmaxPathSum(TreeNode* root){ int val = INT_MIN; int k= hmax(root, val); return max(k, val); }
intmaxProfit(vector<int>& prices){ int t1 = 0, t2 = 1; int vsize = prices.size(); if (vsize <=1||(vsize==1&&prices[1]<prices[0]))return0; int pro = prices[1] - prices[0]; while (t2 < vsize) { if (prices[t2] > prices[t2 - 1]) { for (int i = t1; i < t2; i++) { if (prices[t2] - prices[i] > pro) { t1 = i; pro = prices[t2] - prices[i]; } } } t2++; } return pro; }
题目描述
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
题解
既然可以买多次,那就把赚钱的时候都加起来就行了。
1 2 3 4 5 6 7 8 9 10 11
intmaxProfit(vector<int>& prices){ int vsize = prices.size(); if (vsize <= 1)return0; int pro = 0; for (int i = 1; i < vsize; i++) { if (prices[i] - prices[i - 1]>0) pro += prices[i] - prices[i - 1]; } return pro; }
==题目描述==
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
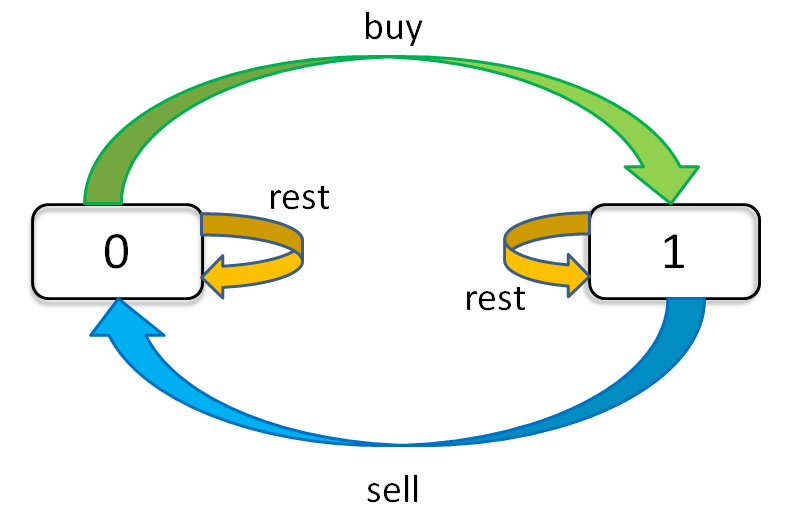
有了上一题 k = 2 的铺垫,这题应该和上一题的第一个解法没啥区别。但是出现了一个超内存的错误,原来是传入的 k 值会非常大,dp 数组太大了。一次交易由买入和卖出构成,至少需要两天。所以说有效的限制 k 应该不超过 n/2,如果超过,就没有约束作用了,相当于 k = +infinity。这种情况是之前解决过的。
intminimumTotal(vector<vector<int>>& triangle){ int high = triangle.size(); if (!high)return0; for (int i = high - 2; i >= 0; i--) for (int j = 0; j<triangle[i].size(); j++) triangle[i][j] += min(triangle[i + 1][j + 1], triangle[i + 1][j]); return triangle[0][0]; }